
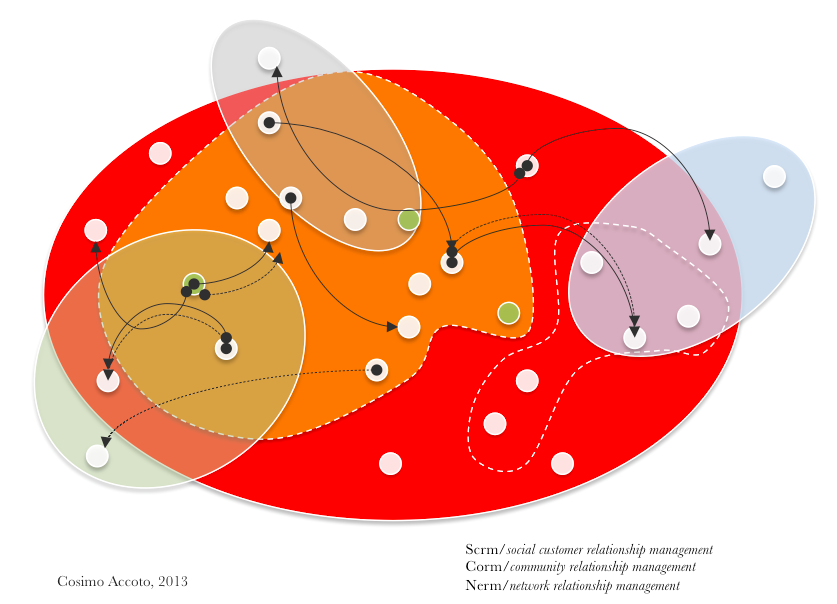
Modeling 3 #bigdata #socbiz (scrm, corm, nerm?)

“Increasingly in the 21st century, our daily lives leave behind a detailed digital record: our shifting thoughts and opinions shared on Twitter, our social relationships, our purchasing habits, our information seeking, our photos and videos—even the movements of our bodies and cars. Naturally, for those interested in human behavior, this bounty of personal data is irresistible” (from Fisher et alii, 2012)
http://research.microsoft.com/pubs/163593/inteactions_big_data.pdf
Note 3
From real-time to subperceptual (and eterogeneity of time in digital age)“A common trivial statement in big data discourse is claiming business and marketing live nowadays in a “real-time” dimension. I think it’s a misleding sentence because is not enough to say “real-time”. In fact, the concept of “human” real-time has a specific sensorial connotation and limitation and is different from the “machinic” real-time that works in a “sub-perceptual” dimension for humans. It’s time to evolve our big data perspective to include and evaluate the relationship between the computational real-time and the bionic real-time” (Cosimo Accoto, 2013)
Note 2: From a “trace” to the “event”
A current trivial discourse correctly underlines the overproduction of “traces” as a by-product of the deployment of digital technologies and networks. If this is a general correct statement, what remains broadly uninvestigated is the ontological and epistemological relation existing between a “trace” and the “event” that generates the trace. We need a more solid investigation (even in term of thermodynamics of a trace as a remnant of an event) about the meaning of a digital trace in the context of a data intensive age (Cosimo Accoto, 2013)
from the abstract:
“Customer Relationship Management (CRM) plays a prominent role in enabling businesses to meet their customers ’ needs, and therefore it acts as a catalyst in the process of creating and delivering value to them. As CRM concerns managing customer knowledge, it can be considered as a subset of Knowledge Management (KM). Therefore, in this study, the effort has been made to propose a Customer Knowledge Management (CKM) process model to compensate the existing lack of a study integrating CRM and KM with the aim of customer value augmentation. In this CKM model, all forms of CRM are employed to support all the phases of CKM. Finally, a home appliances case is studied to illustrate the proposed CKM model” (Journal of Journal of Database Marketing & Customer Strategy Management (2012) 19, 321 – 347)
http://www.palgrave-journals.com/dbm/journal/v19/n4/pdf/dbm201232a.pdf
“This article argues that in an age of knowing capitalism, sociologists have not adequately thought about the challenges posed to their expertise by the proliferation of ‘social’ transactional data which are now routinely collected, processed and analysed by a wide variety of private and public institutions. Drawing on British examples, we argue that whereas over the past 40 years sociologists championed innovative methodological resources, notably the sample survey and the in-depth interviews, which reasonably allowed them to claim distinctive expertise to access the ‘social’ in powerful ways, such claims are now much less secure.We argue that both the sample survey and the in-depth interview are increasingly dated research methods, which are unlikely to provide a robust base for the jurisdiction of empirical sociologists in coming decades. We conclude by speculating how sociology might respond to this coming crisis through taking up new interests in the ‘politics of method’ “(Sauvage and Burrows).
Author: Emma Uprichard
Abstract:
“Recently, Savage and Burrows have argued that one way to invigorate sociology’s ‘empirical crisis’ is to take advantage of live, web based digital transactional data. This paper argues that whilst sociologists do indeed need to engage with this growing digital data deluge, there are longer term risks involved that need to be considered. More precisely, C. Wright Mills’ ‘sociological imagination’ is used as the basis for the kind of sociological research that one might aim for, even within the digital era. In so doing, it is suggested that current forms of engaging with transactional social data are problematic to the sociological imagination because they tend to be ahistorical and focus mainly on ‘now casting’. The ahistorical nature of this genre of digital research, it is argued, necessarily restricts the possibility of developing a serious sociological imagination. In turn, it is concluded, there is a need to think beyond the digitised surfaces of the plastic present and to consider the impact that time and temporality, particularly within the digital arena, have on shaping our sociological imagination” (Emma Uprichard, 2012).
http://www.academia.edu/1786188/Uprichard_E._forthcoming_2012_Being_stuck_in_…
