
“Databases can be understood as the pre-eminent contemporary doing, organising, configuring and performing thing-and-people multiples in sets. Participation, belonging, inclusion and membership: many of the relations that make up the material social life of people and things can be formally apprehended in terms of set-like multiples rendered as datasets. Mid-twentieth century database design derived different ways of gathering, sorting, ordering, and searching data from mathematical set theory. The dominant database architecture, the relational database management system (RDMS), can be seen as a specific technological enactment of the mathematics of set theory. More recent developments such as grids, clouds and other data-intensive architectures apprehend ever greater quantities of data. Arguably, in emerging data architectures, databases themselves are subsumed by even more intensive set-like operations” (Mackenzie).
http://www.lancs.ac.uk/staff/mackenza/papers/mackenzie_database-multiples-sep…Privacy and #Bigdata: a rational response
Abstract (from Social Science Research Network):
“With over a dozen bills pending in both the U.S. and E.U. to “solve” the privacy crisis, perhaps it’s time to take a step back and ask some fundamental questions about information management in the age of big data. Why does “private” information evoke visceral policy responses? Is there a rational model for evaluating information exchange and value? Is intellectual property law the model to apply to personal information, or would licensing work better? This paper, part of the Cato Institute’s Policy Analysis series, traces the historical origins of the “creepy factor” as a conflict between America’s Puritan and frontier origins. It rejects the IP model for personal information and recommends instead a licensing approach — which is largely in place today” (Larry Downes, 2013)
Patterns in empirical data and the structure of the world #bigdata
What do patterns in empirical data tell us about the structure of the world? (James W. McAllister, Synthese (2011) 182:73–87)
“This article discusses the relation between features of empirical data and structures in the world. I defend the following claims. Any empirical data set exhibits all possible patterns, each with a certain noise term. The magnitude and other properties of this noise term are irrelevant to the evidential status of a pattern: all patterns exhibited in empirical data constitute evidence of structures in the world. Furthermore, distinct patterns constitute evidence of distinct structures in the world. It follows that the world must be regarded as containing all possible structures. The remainder of the article is devoted to elucidating the meaning and implications of the latter claim”
http://download.springer.com/static/pdf/573/art%253A10.1007%252Fs11229-009-96…
#Bigdata in the top 10 priorities for Marketing Science
“[…] Priority 6: Big Data. The explosive growth in the sources and quantity of data available to firms is leading them to employ new methods of analysis and reporting, such as machine learning and data visualization. Unless the skill sets of professional marketers evolve, it is likely that some of the activities historically associated with marketing and customer service will migrate to other functional areas of the organization, such as information technology or engineering. Academic work, too, in its assumptions, approaches, theories, models, and methodologies, will increasingly be found inadequate to deal with this change..” […] (extract and image from: Marketing Science, Vol. 31, No. 6, November–December 2012, pp. 873–877)
(selection from Figure 1 A Mapping of Priority Topics Over the Past Quarter Century); image from: Marketing Science, Vol. 31, No. 6, November–December 2012, pp. 873–877)
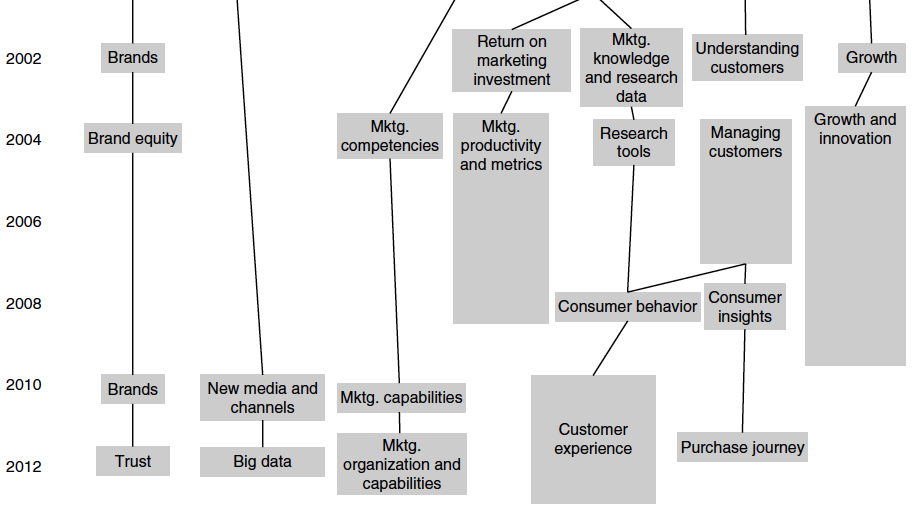
http://mktsci.journal.informs.org/content/31/6/873.full.pdf+html
#Bigdata and the priorities 2012-2014 of Marketing Science Institute
“Priority 1: Insight into People in Their Roles as Consumers. The 2012–2014 Research Priorities call for research in any of the following three distinct subtopics: new methods, new data sources, and new theories. Many MSI members are questioning traditional methods of insight generation, such as surveys and focus groups, and traditional frameworks for thinking about consumption. Long-form surveys are hard to reconcile with today’s modes of communication. The climate is ripe for innovation in the gathering and construction of insights into why people buy and use products and services. With respect to methods, our members want to see evidence of the validity of the application of advanced technologies to generate consumer insights, such as mobile devices used for geopolling, social media monitoring, online or in-store tracking of behavior, and technologies as yet unexplored (for example, augmented reality). With respect to data sources, we are particularly interested to see research on the rapid generation of consumer and business insights from large, relatively unstructured data. With respect to theory, we would like to see applications to consumption, at scale and with evidence of validity, of frontier theories in the social sciences, for example, those from psychology, sociology, and anthropology, but also from less frequently applied disciplines such as linguistics and neuroscience. However, we caution researchers to avoid fragmentary laboratory results, unless there is reason to think that the insights will hold up in the marketplace” (from Marketing Science).
http://mktsci.journal.informs.org/content/31/6/873.full.pdf+html?sid=6db502b9…On the "protocological" mechanisms of Facebook #bigdata
“In this essay, I develop an understanding of a technicity of attention in social networking sites. I argue that these sites treat attention not as a property of human cognition exclusively, but rather as a sociotechnical construct that emerges out of the governmental power of software. I take the Facebook platform as a case in point, and analyse key components of the Facebook infrastructure, including its Open Graph protocol, and its ranking and aggregation algorithms, as specific implementations of an attention economy. Here I understand an attention economy in the sense of organising and managing attention within a localised context. My aim is to take a step back from the prolific, anxiety-ridden discourses of attention and the media which have emerged as part of the so-called ‘neurological turn’ (see Carr, 2012; Wolf, 2007).1 In contrast, this essay focuses on the specific algorithmic and ‘protocological’ mechanisms of Facebook as a proactive means of enabling, shaping and inducing attention, in conjunction with users” (Taina Bucher, Culture Machine, 3, 2012)
http://www.culturemachine.net/index.php/cm/article/view/470/489"Scraping the Social? Issues in real-time social research" (2012) #bigdata
by Noortje Marres, Goldsmiths, University of London and Esther Weltevrede, University of Amsterdam (2012)
from the abstract
“What makes scraping methodologically interesting for social and cultural research? This paper seeks to contribute to debates about digital social research by exploring how a ‘medium-specific’ technique for online data capture may be rendered analytically productive for social research. As a device that is currently being imported into social research, scraping has the capacity to re-structure social research, and this in at least two ways. Firstly, as a technique that is not native to social research, scraping risks to introduce ‘alien’ methodological assumptions into social research (such as an pre-occupation with freshness). Secondly, to scrape is to risk importing into our inquiry categories that are prevalent in the social practices enabled by the media: scraping makes available already formatted data for social research. Scraped data, and online social data more generally, tend to come with ‘external’ analytics already built-in”
https://wiki.digitalmethods.net/pub/Dmi/PapersPublications/Marres_Weltrevede_…
"Data before the Fact" (Daniel Rosenberg, 2012) #bigdata
“From the beginning, data was a rhetorical concept. “Data” means that which is given prior to argument. As a consequence, its sense always shifts with argumentative strategy and context—and with the history of both. The rise of modern natural and social science beginning in the eighteenth century created new conditions of argument and new assumptions about facts and evidence. But the pre-existing semantic structure of the term “data” gave it important flexibility in these changing conditions. It is tempting to want to give data an essence, to define what exact kind of fact it is. But this misses important things about why the concept has proven so useful over these past several centuries and why it has emerged as a culturally central category in our own time. When we speak of “data,” we make no assumptions about veracity. It may be that the electronic data we collect and transmit has no relation to truth beyond the reality that it constructs. This fact is essential to our current usage. It was no less so in the early modern period; but in our age of communication, it is this rhetorical aspect of the term that has made it indispensable” (“Data before the Fact”, by D. Rosenberg, 2012).
http://courses.ischool.berkeley.edu/i218/s12/Rosenberg.Data..draft.pdf
Investigating the history of #bigdata term
“The Origins of ‘Big Data’ : An Etymological Detective Story”
(by Bits, The New York Times)
http://bits.blogs.nytimes.com/2013/02/01/the-origins-of-big-data-an-etymologi…
