Imprese e tecnologie: una sfida culturale (*)
La gestione contemporanea di economia e business sollecita sempre più le culture d’impresa ad immergersi strategicamente dentro le molte, nuove e sorprendenti dimensioni dell’orizzonte tecnologico in divenire. Una sfida oltremodo significativa nel momento in cui -come si sostiene da molti- la tecnologia non è più semplicemente a supporto o ad abilitazione del business, ma è fondamentalmente essa stessa il business. Un’affermazione da contestualizzare, ma è certamente vero che la nuova articolazione operativa della triade “mondo, mente, macchina” sta producendo interessanti collassi delle possibilità tecniche in attualità economiche. È su queste tecnicalità che credo vada oggi esercitato un pensiero strategico e manageriale sofisticato. In questa prospettiva, propongo qui una prima e breve esplorazione su quattro orizzonti: cloud nativity, edge ecosystem, chaos engineering, architecture observability.
La nuvola nativa (cloud nativity)
Le metafore metereologiche e geografiche della computazione si sono ampliate negli ultimi decenni. Per affrontare criticità architetturali come riservatezza, latenza, sicurezza, connessione ed efficienza, le risorse computazionali a disposizione delle imprese e del business si sono stratificate nel tempo e localizzate nello spazio. Di fatto, operano su livelli sovrapposti e interconnessi dai nomi evocativi. Così, cloud computing, fog computing, edge computing mappano, oggi, figurativamente i dove della computazione, le sue locazioni: sulla nuvola (servizi e applicazioni in cloud), nella nebbia (sfruttando i fog gateway intermedi) o al margine del mondo (nei nodi di edge dell’internet delle cose). C’è, dunque, una topologia e molte topologie per in-formare il mondo, una geografia e anzi più geografie del processare l’informazione, una e molteplici spazialità dove l’intelligenza dei mercati e delle imprese si incorpora. Queste metafore locative non devono però trarci in inganno. Queste diverse “collocazioni” (luoghi) della computazione sono, infatti, anzitutto e soprattutto “configurazioni” (modi) della computazione. Non è, dunque, strategicamente solo una questione di “dove” sono i server, ma del “come” si possono progettare servizi e valore in modalità nuove per clienti, consumatori, colleghi e partner. Per questo, la nuvolo-natività (cloud nativity) è altra cosa dal trasferimento sic et simpliciter di preesistenti applicazioni e servizi sulla nuvola come erroneamente pensano ancora molte imprese. Non basta cioè semplicemente spostare in cloud il business esistente per beneficiare delle potenzialità della nuvola, attenzionando e negoziando ovviamente le sue vulnerabilità e anche le complessità dei modelli finanziari connessi (cloud finops). Un business migrante sulla nuvola è cosa diversa da un business nativo della nuvola. Lo stesso si può dire per la computazione al margine del mondo (edge computing) propria dell’internet delle cose. La computazione incarnata dai sensori e dagli attuatori dei nodi di edge e abilitata dai dispositivi di collegamento intermedio dei fog gateway non è semplicemente una diversa localizzazione dove processare l’informazione. Filosoficamente, questa computazione sempre più spazializzata e automatizzata è più un nuovo modo d’essere del mondo che un luogo dello stare al mondo. Dunque, più una questione ontologica che topologica.
L’impresa sconfinante (edge ecosystem)
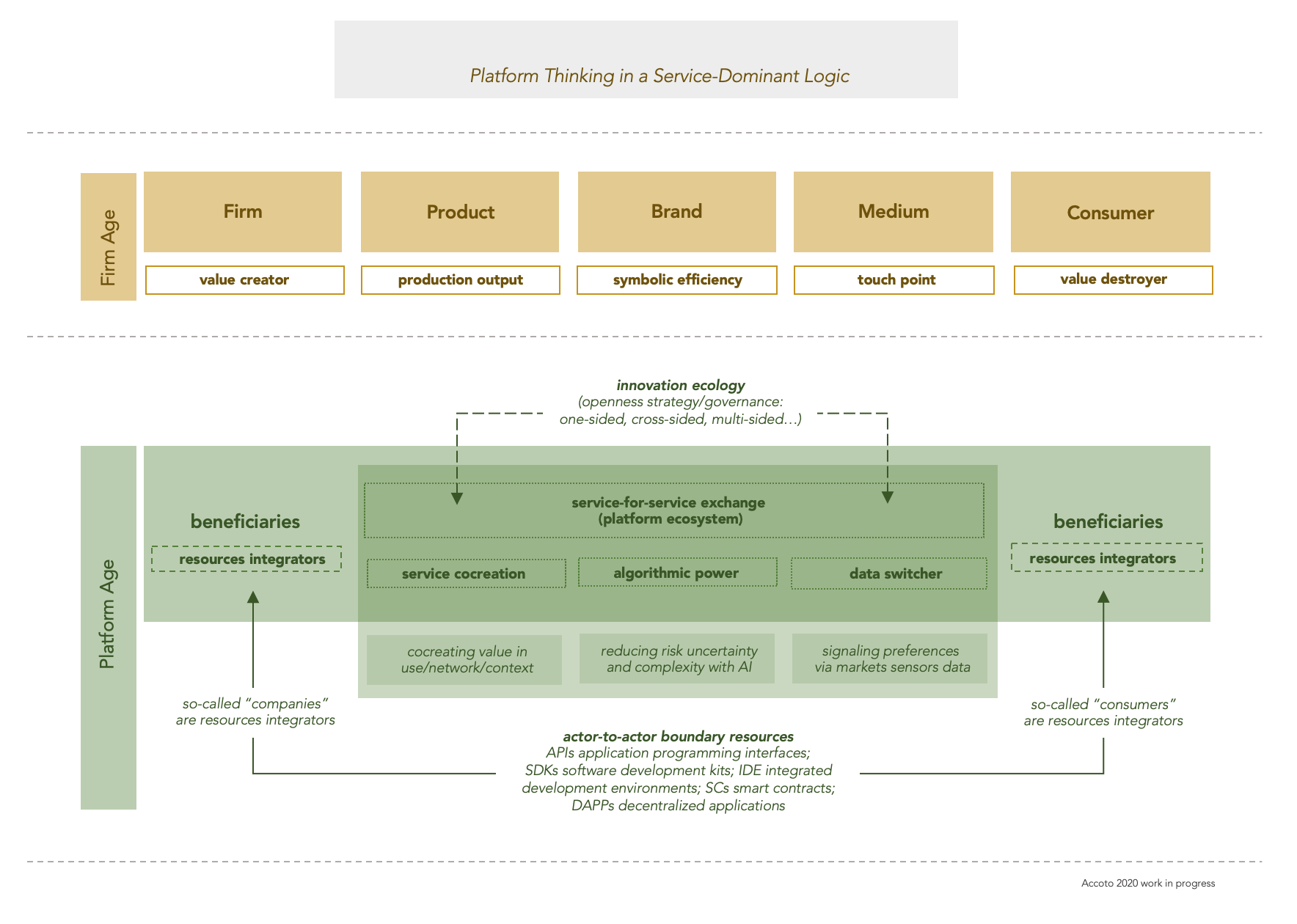
Nell’era degli ecosistemi di servizio a piattaforma, la cocreazione di valore è un processo catallattico (di scambio) emergente ed esperienziale con cui attori economici anche estremamente eterogenei -umani e non umani- automaticamente e contestualmente mobilitano e integrano risorse di varia natura (operanti e operande, tangibili quanto intangibili). Sfruttando le capacità di scala degli effetti di rete (network effects lato domanda -e non solo lato offerta- same-side e cross-side), queste ecologie cogenerative di valore stimolano e orchestrano interazioni multilaterali. Lo fanno in virtù di stili di leadership e regole di governance non esclusivamente contrattuali (come accade invece con reti, partner o catene di fornitura tradizionali). Una delle strategie competitive per rendere operativa questa apertura ecotecnica delle imprese all’integrazione di risorse e allo scambio di servizi è la gestione delle interfacce di programmazione applicativa (API management). Il paradigma tecnico dello sconfinamento d’impresa ha visto storicamente vari approcci: dai programmi di chiamata di procedura remota (RPC) alle architetture orientate al servizio (SOA) al modello risorse-centrico leggero (REST). Fino alle più contemporanee e nuove interfacce di ‘contrattazione’ applicativa (ACI o application contracting interfaces secondo Lauslahti e non più solo application programming interfaces) vale a dire gli smart contracts su architetture e piattaforme blockchain. Molti gli obiettivi dello sconfinamento: interoperabilità, produttività, monetizzabilità per citare i principali. A fronte di queste opportunità, un’esplorazione strategica della liminalità d’impresa è allora sempre più rilevante. In particolare, è rilevante l’analisi delle ‘risorse di confine’ (boundary resources): non solo per l’appunto API, ma anche SKD (software kit development), IDE (integrated development environment), DAPP (decentralized application) e SC (smart contracts). Sono tutte modalità con cui l’impresa sconfina dal perimetro delle sue infostrutture per aprirsi allo scambio multilaterale e all’integrazione di risorse esterne. Pensiamo anche alle recenti direttive di PSD2 per le banche. Un orizzonte sempre più rilevante anche nella prospettiva dello sviluppo di strategie di “coopetizione” che hanno lo scopo di bilanciare dinamicamente collaborazione e competizione. In queste ecologie, le imprese hanno la possibilità inoltre di immaginare ‘esperimenti di business’ e di fare business experimentation di modelli e servizi.
Il caos evocato (chaos engineering)
Tecnicamente, con l’espressione chaos engineering si individua l’idea e la pratica ingegneristica di attaccare intenzionalmente, preventivamente e sempre più automaticamente le proprie architetture informatiche (e di business). La finalità è quella di poter conoscere e testare sicurezza, consistenza e resilienza delle proprie infrastrutture/infostrutture. Con questo obiettivo, si pianifica e si attua l’iniezione deliberata e arrischiata di caos entropico nei sistemi mentre sono in effettiva produzione (quindi non in ambienti di prova o di sviluppo come avviene di solito). Così fanno, ad esempio, i chaos engineers di Netflix e di molte grandi piattaforme digitali cercando deliberatamente di far fallire l’erogazione. Questa esplorazione sperimentale stressante è in grado di individuare preventivamente punti di debolezza, insospettabili criticità operative, interruzioni o fallimenti del servizio ai clienti. Tuttavia, filosoficamente, il passaggio di paradigma per le imprese tradizionali è spaesante e paradossale quantomeno rispetto alla gestione più classica di rischi e vulnerabilità. Significa, infatti, che il fallimento non lo si può estromettere del tutto dal tempo né lo si può semplicemente allontanare nel tempo massimizzando la durata tra un fallimento e l’altro (il mean time between failure o MTBF nel linguaggio tecnico). Neppure si può solo cercare di recuperare il fallimento nel tempo più breve possibile minimizzando il momento della sua riparazione (il mean time to repair o MTTR per i tecnici). Paradossalmente, allora, l’unica via agibile per non farlo accadere è farlo accadere. Quanto prima. Sollecitando cioè strategicamente il tempo del suo manifestarsi. Questa prospettiva non riguarda solo la verifica della tenuta dei sistemi rispetto a fallibilità endogene e nascoste delle proprie architetture divenute sempre più complesse, intricate e impossibili da conoscere nelle sole fasi di design, progettazione e realizzazione. Vale anche per le vulnerabilità da fattori esterni a cui rispondere con strategie adeguate. Così come accade, ad esempio, per le pratiche della cybersicurezza a “vasetto di miele” (come dicono gli esperti, honeypot). Queste ultime invece di essere solo adattive o responsive sono più propriamente adescative. La cybersicurezza per adescamento (deception) degli attacchi e non solo per intercettamento (detection) degli attacchi crea, cioè, le condizioni per l’intrusione malevola lasciando, ad esempio, false porte informatiche aperte per attirare e invogliare gli attaccanti. Per gestire l’attacco, devo strategicamente sollecitarlo ed evocarlo.
L’osservazione sparsa (architecture observability)
Il tracciamento distribuito (distributed tracing) è, indubbiamente, un tema tecnologico chiave nel passare dal monitoraggio delle vecchie architetture informatiche monolitiche all’osservabilità delle contemporanee ecologie di microservizi distribuiti e automatizzati. Il passaggio dal monolite al microservizio è rilevante al fine di incrementare l’autonomia dei team di sviluppo, ridurre il time to market delle soluzioni, scalare nei costi e nelle risorse l’efficienza o aumentare robustezza e resilienza del sistema. Ma aumenta la complessità della business intelligence dell’infostruttura. Come, per fare un caso, poter osservare e misurare una transazione economica di un servizio di mobilità on demand per valutarne le performance operative. Tuttavia, chiediamoci, se e quanto e come è osservabile un’attività di business che emerge tra architetture, piattaforme e applicazioni sparse in rete? L’osservabilità di un’architettura distribuita è tecnicamente e materialmente sempre più difficoltosa. Di fatto, l’operazione di osservazione di cosa sta accadendo in un sistema reticolare esaminando le risultanze del sistema stesso (la sua observability come la chiamano i tecnici) sta crescendo in complessità. Per questo, ad esempio, in Uber gli ingegneri hanno dovuto reimmaginare e riprogettare il sistema di tracciamento e di metriche dei loro 2400 microservizi. Infatti, il semplice gesto di un cliente che clicca sulla loro app, attiva una ‘transazione distribuita’ che richiede l’azione congiunta di dozzine di microservizi differenti sparsi in rete per poter essere soddisfatta. Se qualcuno di questi fallisce, non è facile capire dove e perché. Occorre monitorare reti sparse e addensate tanto quanto reti fisiche e virtualizzate (con analisi multipercorso o multipathing) oppure monitorare i microservizi per i quali è sempre più sfuggente individuare il nodo finale di una comunicazione in rete (end-point). Ma tutto questo non è solo difficile per le questioni tecniche qui sintetizzate. Aggiungerei anche filosoficamente. Perché, a ben guardare, l’osservazione di un evento distribuito è, al contempo, un evento distribuito di osservazione. E dunque, fare business e operational intelligence dei servizi distribuiti richiede strategicamente nuove capacità operative di analisi e nuovi strumenti teorici. Un servizio distribuito non è solo un contesto più complesso dell’osservare, ma è proprio un modo nuovo dell’osservare i mercati.
In conclusione, allora, in un’economia automatizzata l’emergere di nuove tecnicalità e operatività di business richiede di necessità l’apertura della cultura d’impresa a nuove dimensioni di pensiero strategiche. Incrociando culturalmente tecnologia, business e management.
Accoto 2020
(*) work in progress – rielaborazione da un mio articolo di dicembre 2019 uscito su Parole di Management, Este