Officially hit international store shelves >> “In Data Time and Tide. A Surprising Philosophical Guide to Our Programmable Future” (Accoto, Bocconi University Press, 2018). More info about the English version of my book “Il Mondo Dato” here

Officially hit international store shelves >> “In Data Time and Tide. A Surprising Philosophical Guide to Our Programmable Future” (Accoto, Bocconi University Press, 2018). More info about the English version of my book “Il Mondo Dato” here
“Software, processes, computations—these are some of the conventional terms for the most important “stuff” in this domain. Regardless of the words we use, the software has an intriguing dual nature. On one hand, software is something real that can affect the world directly; on the other hand, in some ways software is just the shadows cast by computational engines as they run. As other writers have observed, programming is more like the casting of magic spells than like writing literature or building machines. The effects of programs can take place without the participation of a reader, in contrast to the nature of literature; but the material of a program is more like the words of a novelist than like the physical materials of other engineering disciplines” (Mark Stuart Day, Bits to Bitcoin, MIT Press 2018)

“… we have 32 papers here that represent the current state of the art in the philosophy of AI. We grouped the papers broadly into three categories: “Cognition– Reasoning–Consciousness”, “Computation–Intelligence–Machine Learning” and “Ethics–Law” (2018)

L’economia digitale, paradossalmente, manca di un’analisi filosofica profonda di cosa è un “oggetto digitale”. Una lacuna che rischia di aggravarsi nel momento in cui vengono emergendo criptosistemi che di un’economia della creazione, conservazione e circolazione di oggetti digitali fanno un utilizzo intenso oltre che la ragione prima della loro esistenza. Più in specifico, creazione, conservazione e circolazione di “oggetti-valori” digitali senza duplicazione inflazionaria (scarsità digitale) e senza centralizzazione fiduciaria (trust protocollare). In sintesi estrema, questa è la natura e la finalità dell’emergente paradigma culturale e protocollo tecnologico popolarizzato con il termine di blockchain e, più complessivamente, di un’economia “post-bizantina”, come l’ho chiamata provocatoriamente. Nel caso della neonata criptoeconomia, questi oggetti-valori digitali prendono l’etichetta complessiva di “cryptoasset” e sono categorizzati in entità differenti. Vari i criteri di qualificazione così come i modelli interpretativi, oltre che in costante evoluzione.
Le classificazioni correnti sono orientate ad individuare tre macro-gruppi con proprietà distinte: a) security o investment token; b) utility o network token; c) currency e commodity token. Si trovano anche, a complicare il panorama, altre etichette o specificazioni: per security token (share-like, equity, fund, derivate, ownership token), per utility token (application, infrastructure, governance, work, burn&mint token), per currency token (native coin, payment token, stable coin, transaction coin) e così via. In alcuni casi si tratta di varianti lessicali. In altri casi siamo di fronte a oggetti-valori digitali con proprietà -ad esempio legali- anche molto differenti tra loro. Alcuni analisti semplificano individuando solo due gruppi di oggetti-valori digitali: i token da investimento e i token da utilizzo. Anzitutto, però, chiediamoci: cosa è un “oggetto digitale” e qual è il suo modo di esistenza? Qual è l’ontologia di un oggetto digitale, direbbero i filosofi? E in che senso (e se e come) si distingue da un oggetto naturale e da un oggetto tecnico?
O, per essere più concreti, quando Satoshi Nakamoto scrive -nel suo paper fondativo del protocollo di rete Bitcoin- “definiamo una moneta elettronica come una catena di firme digitali”, che statuto ontologico dobbiamo assegnare a questo oggetto digitale (catena di firme digitali) progettato dal suo creatore per fungere da moneta? ….
(Accoto 2018, work in progress)

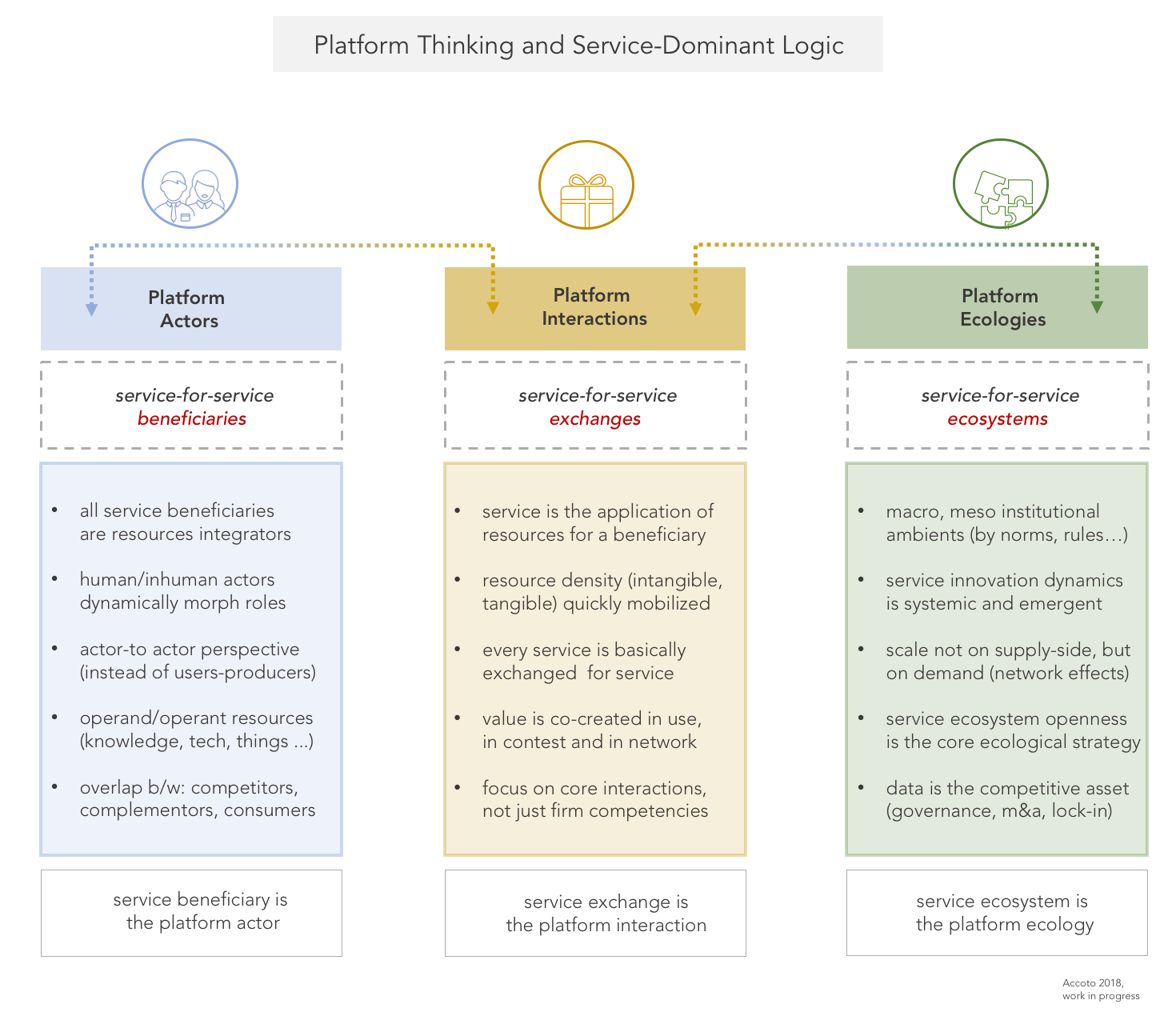
Platform thinking e service-dominant logic: un mio schema di sintesi per mappare nei modelli a piattaforma le logiche service-dominant di Vargo e Lusch (Accoto 2018, work in progress)
Dalle APIs (application programming interfaces) alle ACIs (application contracting interfaces)
“Contracts in themselves have also not been formerly perceived as boundary resources, in the sense that the network effects of a platform ecosystem could be boosted by opening up so-called application contracting interfaces, ACIs (cf. application programming interfaces, APIs). This would enable the creation of more highly automated digital contracting mechanisms, process automation that reaches further beyond companies’ own information systems, as well as more automated and more dynamic networks of contracting parties” (Expanding the Platform: Smart Contracts as Boundary Resources, Lauslahti et alii, 2018)

The Deep Learning Revolution, MIT Press, 2018 – forthcoming
“In this book, Terry Sejnowski explains how deep learning went from being an arcane academic field to a disruptive technology in the information economy. Sejnowski played an important role in the founding of deep learning, as one of a small group of researchers in the 1980s who challenged the prevailing logic-and-symbol based version of AI … Sejnowski prepares us for a deep learning future”

La necessaria focalizzazione sulle meccaniche ingegneristiche della tecnologia blockchain rischia di sotto attenzionare le dimensioni filosofiche fondative di cos’è un “registro”, insieme alle logiche temporali che istanzia e alle sue implicazioni socioculturali più ampie.
Il registro nella sua forma più astratta è storicamente una tecnologia della memoria sociale dello stato del mondo in un dato momento. Ha dunque, primariamente, una funzione “epistemica” in quanto è in grado di creare e conservare, ad ogni dato momento, la conoscenza e la verità dello stato di entità e relazioni nel tempo. Ma ha anche una funzione “istitutiva” in quanto a partire da quello stato di conoscenza e verità consente di attivare e validare cambiamenti futuri dello stato delle cose. Funzione epistemica e funzione istitutiva sono a loro volta intrecciate a logiche temporali.
In uno schema semplificato e seguendo alcune prime suggestioni, proviamo ad esplorare e ad accennare sia pur brevemente, a queste dimensioni temporali che incrociano ingegneria del registro e filosofia del tempo.
Primariamente, la blockchain è chiamata a istanziare una logica filosofica temporale cosiddetta “incrementista” (i filosofi del tempo la chiamano growing block view o teoria del blocco crescente). Il presente -che nell’attuale blockchain di Bitcoin dura circa 10 minuti, cioè il tempo di produzione e pubblicazione di un nuovo block– è rappresentato dall’ultimo blocco pubblicato che è il margine accrescitivo (ultimo fino a quel momento) di una catena di blocchi a solo accodamento di dati. Il passato -catena dei blocchi ad un dato tempo- non si può modificare così come accade, in effetti, anche per il passato storico tout court (è sentimento comune che non si possa cambiare quello che è accaduto). Le transazioni -nel nostro caso, ad esempio, gli scambi di bitcoin- persistono componendo il catalogo complessivo delle entità digitali create, conservate e circolate fino ad un dato momento. Il loro modo di esistenza in quanto oggetti digitali può variare nel corso del tempo: input, output, unspent transaction output o utxo….
Con gli smart contract, invece, la blockchain è chiamata a istanziare fortemente anche un’altra logica filosofica del tempo, quella che potremmo chiamare “erosionista (i filosofi del tempo la qualificano come shrinking block view o teoria del blocco decrescente). Nella blockchain di Ethereum questa dimensione è particolarmente visibile. Potremmo dire, allora, che il presente – che nella blockchain di Ethereum dura pochi secondi (5-30), cioè il tempo di produzione e pubblicazione di un nuovo blocco- è il margine attuale della catena di blocchi a venire che viene erosa, progressivamente, in relazione ai futuri possibili emergenti. C’è naturalmente ancora la dimensione incrementale, ma quella proiettiva e oracolare con codice software che istanzia logiche di business (ad esempio: if this, then that; run until that…) aggiunge nuovo valore. Tipicamente, gli oracoli (oracles, sono fonti informative terze, esterne alla blockchain che alimentano i contratti intelligenti) contribuiscono con i loro dati all’emergere di questi futuri potenziali. Notificando gli eventi trigger agli smart contract, erodono il nuovo blocco dal futuro portandolo così verso il presente e poi il passato….
(Accoto 2018, work in progress, continua)
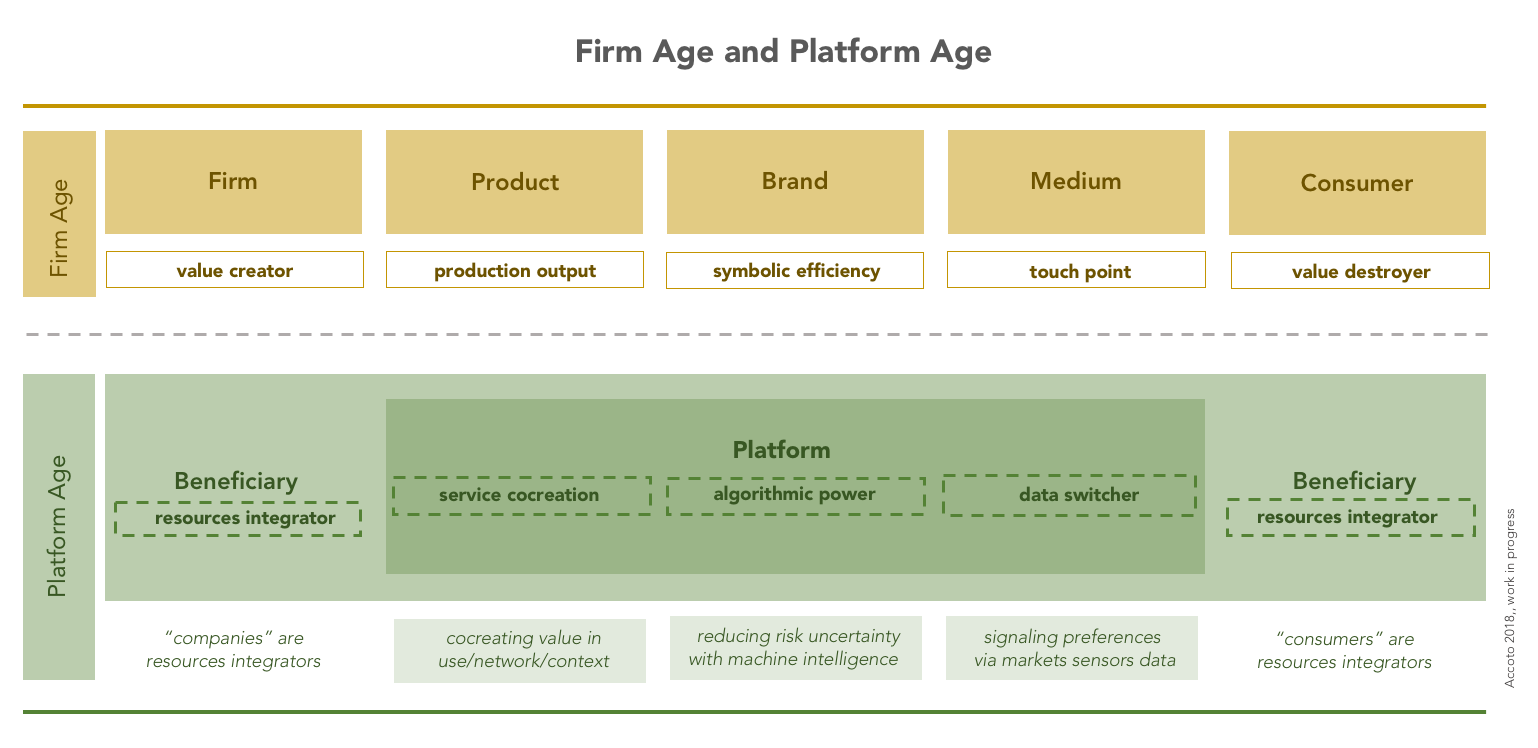
[un passaggio epocale: da impresa a piattaforma] … the paradigm shift from firm to platform (or “platfirm” as I renamed it) in a service-dominant logic and the key strategic pillars for a successful platform transformation (Accoto 2018 – work in progress)