
“Come si progetta orientati al/dal digital twin? Ma prima ancora, che cos’è un digital twin, un gemello digitale? Copia, replica, rappresentazione? Più in astratto, direi che è una simulazione computazionale del mondo nel suo prodursi (di prodotti, processi, produzione in esecuzione). Ma cos’è, filosoficamente, una simulazione computazionale al di là delle tecnicalità di codice, sensori, dati, algoritmi e protocolli? È un dispositivo epistemico -dicono i filosofi- in grado di ridurre lo scarto (ontologico) esistente tra mondo (fisico) e modello (matematico). Dunque, il digital twin non è semplicemente -come si sostiene- replica virtuale o copia digitale del mondo. Queste simulazioni (ad es. diagnostico-prognostiche on-board/off-board di asset fisici industriali in attività) sono, piuttosto, una leva strategica, funzionale o di business, fondamentale. È, infatti, in questa riduzione dello scarto ontologico che possiamo pensare e progettare nuove opportunità di cocreazione di valore e dinamiche di mercato. Un design che voglia orientarsi al o essere orientato dal digital twin richiede, allora, a imprese e manager di allenarsi ad una rinnovata filosofia del simulacro” (Accoto 2020)
“How do you design oriented to/by the digital twin? But before that, what is a digital twin? A copy, a replica, a representation? More abstractly, I would say that it is a computational simulation of the world in its production (of products, processes, productivity in execution). But what is, philosophically, a computational simulation beyond the technicalities of code, sensors, data, algorithms, and protocols? It is an epistemic device – philosophers say – capable of reducing the (ontological) gap existing between the (physical) world and the (mathematical) model. Therefore, the digital twin is not simply – as claimed – a virtual replica or a digital copy of the world. These simulations (e.g. on-board/off-board diagnosis and prognosis of physical industrial assets in operation) are rather a fundamental strategic -functional or business- lever. Indeed, it is in this reduction of the ontological gap that we can think and plan new opportunities for co-creation of value and new market dynamics. A design that wants to orient itself to or be oriented by the digital twin, therefore, requires companies and managers to train themselves in a renewed philosophy of the simulacrum “(Accoto 2020)


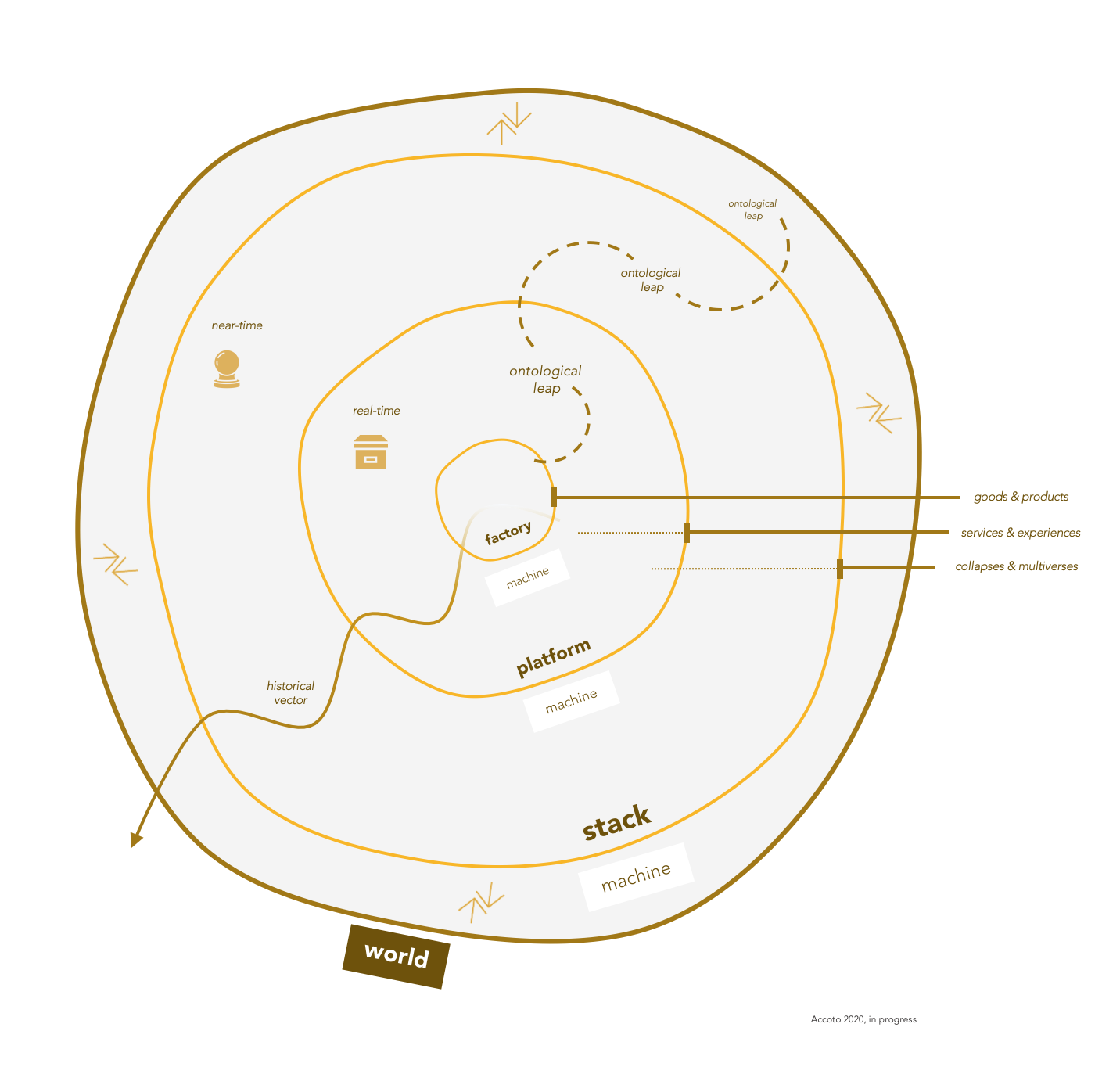
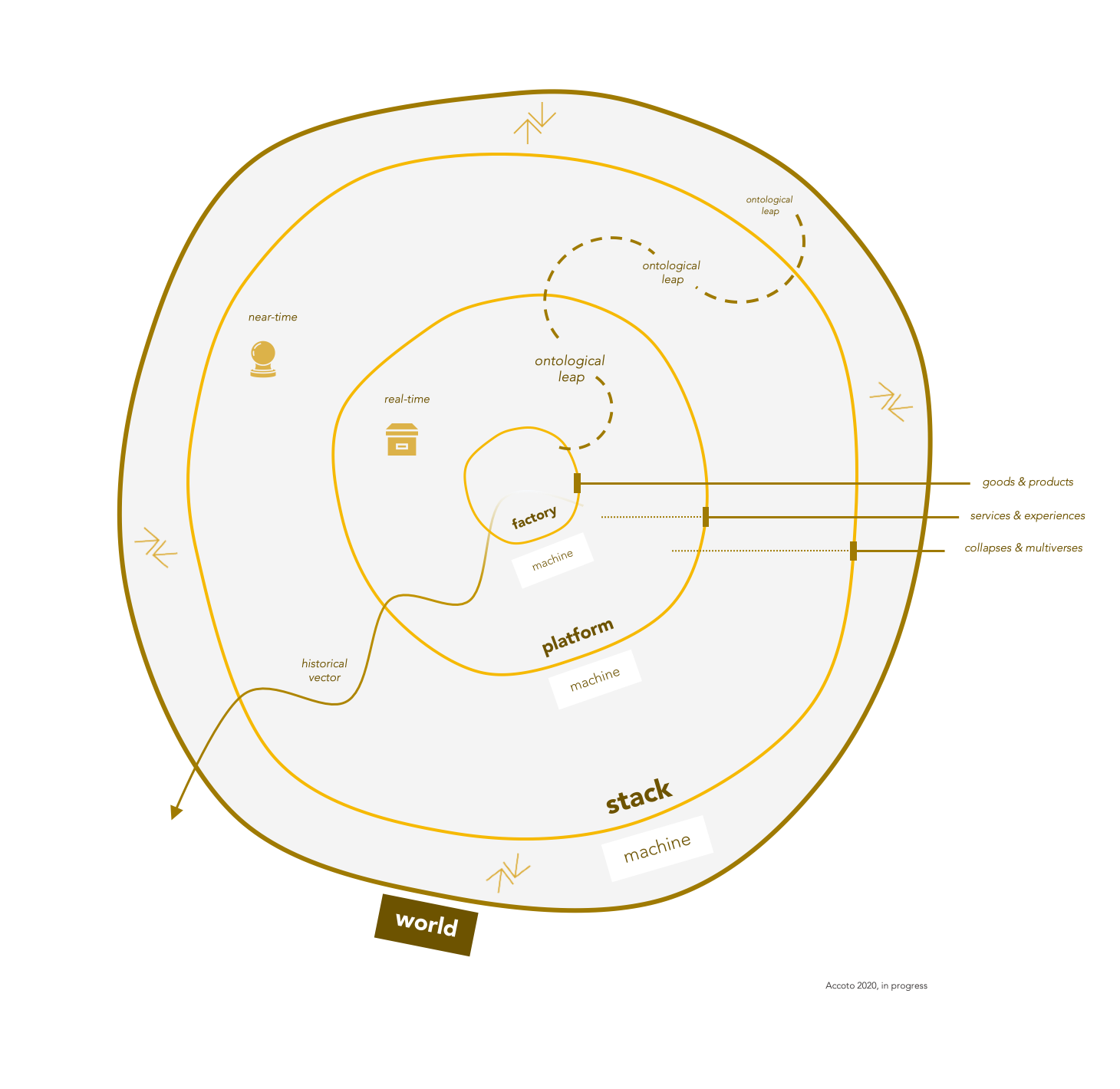


“La metafora ecologica dell’ecosistema è sempre più adoperata per interpretare fenomeni economici ad alta interconnessione e modularità come i business a piattaforma, i mercati a più versanti, le reti decentralizzate, i criptosistemi. E, sicuramente, quella ecosistemica è una lettura che offre significativi elementi analitici ed esplicativi. Insieme a questa, credo possa essere interessante incrociare ed esplorare anche un’ulteriore prospettiva. Traslando in questo caso non gli orientamenti biologici, ma le modellizzazioni quantistiche. Un’interpretazione della meccanica quantistica sostiene, ad es., che un sistema quantistico probabilistico collassa in uno stato determinato solo quando è oggetto di misurazione. Se immaginiamo, allora, l’attuale computazione planetaria (come stack di infostrutture distribuite di sensing e mining) come macchina astratta eminentemente misurativa, le sue operazioni di misurazione sarebbero l’atto che fa collassare in uno specifico stato d’esistenza il multiverso delle possibilità del mondo (e del business). È, allora, quell’atto di misurazione che decide e porta all’esistenza un reale determinato rispetto alle sue multiversali configurazioni possibili?” (Accoto 2020 in progress)
From an ecosystemical relation to a multiversal collapse (Accoto 2020)
“The ecological metaphor of the ‘ecosystem’ is increasingly used to interpret economic phenomena related to high interconnection and modularity such as platform businesses, multi-sided markets, decentralized networks, cryptosystems. Of course, the ecosystem is a great metaphorical frame that offers significant analytical and hermeneutical contributions. In parallel, I think it may be interesting to evoke and explore a further perspective. Translating in this case not biological orientations, but quantum intuitions. An interpretation of quantum mechanics argues, for example, that a probabilistic quantum system collapses into a given state only when it is measured. Similarly, if we imagine the current planetary computation (as a stack of distributed sensing and mining infostructures) as an eminently abstract measurement machine, its measurement operations would be the act that causes the multiverse of possibilities to collapse into a specific state of existence of the world (of the business). It is, therefore, that act of measurement that decides and brings to existence a specific real selected from its multiversal possible configurations? ” (Accoto 2020 in progress)